

Web scraping @edge con Raspberry PI, AWS Firehose & Glue
Cosa si intende per “Web scraping @edge” o “Intranet web scraping”? La possibilità di estrarre dei dati da un sito web privato, cioè da una risorsa o un dispositivo IoT non raggiungibile pubblicamente. Per quale motivo dovrebbe interessarci? Per raccogliere dati disponibili solo privatamente e per poterli processare (sul cloud in scala) al fine di produrre informazioni e insights.
Scopo di questo progetto è monitorare l’attivazione di alcuni sensori di motion detection normalmente utilizzati nell’impianto antifurto di casa. Essendo un sistema chiuso e proprietario, per ovvi motivi di sicurezza, ho utilizzato un normalissimo Raspberry PI in rete locale per effettuare scraping della UI della centrale di allarme Paradox della mia abitazione ed inviare i dati raccolti in (near) realtime ad AWS Kinesis Data Firehose per successiva elaborazione. Dopo aver raccolto i dati per alcune settimane, mi sono divertito su un Notebook a identificare le stanze più utilizzate e i vettori di spostamento più frequenti.
Vediamo lo schema generale.
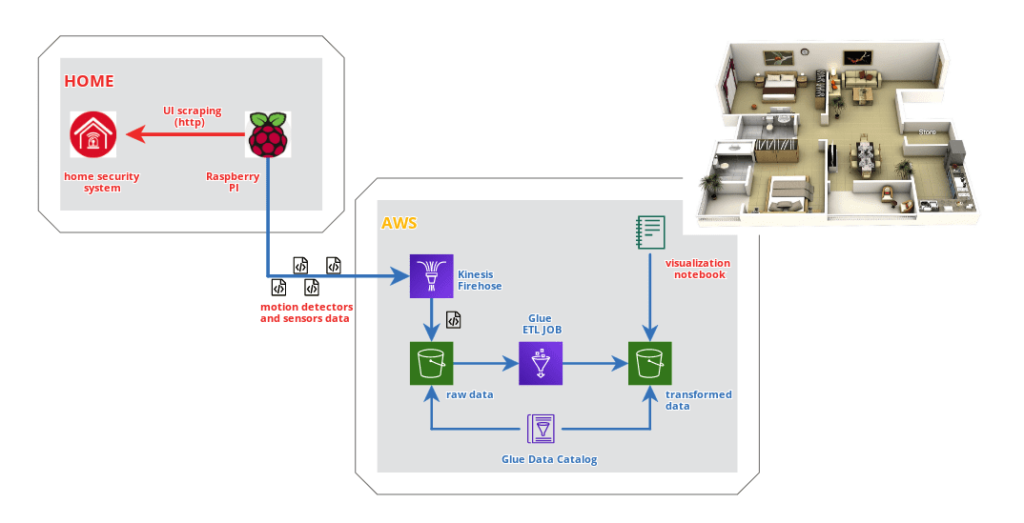
Il repository progetto è disponibile su Github.
Web scraping con Raspberry PI e Selenium
Avendo già esperienza nell’utilizzo di Selenium, ho deciso di adottare lo stesso framework anche in questo progetto. Rispetto al passato, la sfida è stata utilizzarlo su Raspberry PI, opzione che ha portato ad adottare Firefox al posto di Chromium, in quanto, quest’ultimo, non più ampiamente supportato su architettura ARM.
La web page della centrale Paradox (in realtà del suo modulo lan IP150), disponibile solo in rete locale e previa autenticazione, si presenta come nella seguente immagine.
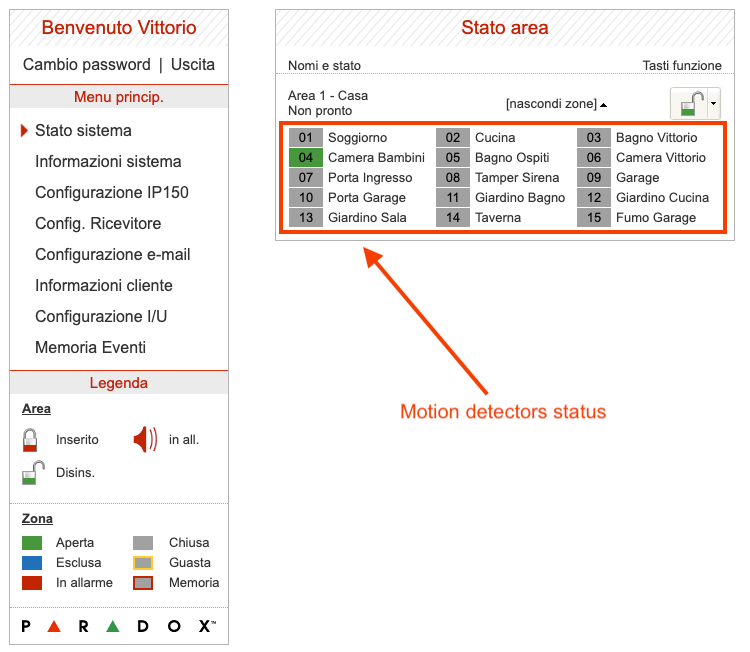
Il nostro scopo è catturare lo stato di ciascuna zona – o sensore motion – al fine di raccogliere dati storici da inviare al cloud. Essendo il sistema Paradox un sistema chiuso che non prevede possibilità di integrazione con altre soluzioni, il web scraping in polling rappresenta l’unica via percorribile.
Come effettuare il login? Come detto, utilizzeremo Selenium e Firefox in uno script Python per automatizzare l’operazione. Ecco un esempio del codice utilizzato.
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.firefox.options import Options
from selenium import webdriver
import os
from time import sleep
from pyvirtualdisplay import Display
def paradox_login():
# Set screen resolution
display = Display(visible=0, size=(1366, 768))
display.start()
# Open Firefox
options = Options()
options.headless = True
driver = webdriver.Firefox(
executable_path='/usr/local/bin/geckodriver',
options=options)
# Open homepage
ipaddress = os.environ['PARADOX_IPADDRESS']
print('Opening Paradox at address: {}'.format(ipaddress))
driver.get('http://{}'.format(ipaddress))
print('Waiting a moment..')
sleep(5)
#Login
usercode, password = os.environ['PARADOX_USERCODE'],
os.environ['PARADOX_PASSWORD']
print('Login..')
user_elem = driver.find_element_by_id("user")
pass_elem = driver.find_element_by_id("pass")
user_elem.clear()
user_elem.send_keys(usercode)
pass_elem.clear()
pass_elem.send_keys(password)
pass_elem.send_keys(Keys.RETURN)
if __name__ == "__main__":
paradox_login()Effettuato il login possiamo dedicarci a catturare lo stato dei sensori.
driver.get('http://{}/statuslive.html'.format(ipaddress))Compiendo periodicamente delle richieste HTTP/GET come quella mostrata, potremo ottenere la pagina HTML da sottoporre a parsing per estrarre le informazioni di stato. Non mi soffermo sull’implementazione del parsing, semplice esercizio Python di estrazione di stringhe. L’intero codice sorgente è disponibile nel repository del progetto.
Supponendo ora di avere a disposizione un dictionary (firehose_record) con i dati relativi a ciascun sensore, quali nome e stato di attivazione, saremo in grado di spedirlo in formato JSON ad uno stream AWS Firehose precedentemente configurato per memorizzare i contenuti in un bucket S3.
import boto3
import json
import os
producer = boto3.client('firehose')
response = producer.put_record(
DeliveryStreamName=os.environ['KINESIS_STREAM'],
Record={
'Data': json.dumps(firehose_record) + '\n'
}
)Docker
Per concludere, ho scelto di eseguire lo script di scraping in un container docker: partendo dall’immagine Python 3.8 per architettura ARM32, è necessario installare Firefox, Selenium ed il relativo driver Gecko, oltre ad altre dipendenze.
Il dockerfile utilizzato nel progetto è riportato di seguito.
AWS Glue
I nostri dati grezzi sono automaticamente raccolti in un bucket S3. Come iniziare ad utilizzarli?
Per prima cosa eseguiamo un crawler di AWS Glue Data Catalog per creare un database (my-home) e una tabella (paradox_stream) da poter utilizzare successivamente in un job ETL.
Iniziamo il nostro script Python mostrando proprio lo schema identificato dal crawler.
from pyspark.context import SparkContext
from awsglue.context import GlueContext
glueContext = GlueContext(SparkContext.getOrCreate())
paradox_stream = glueContext.create_dynamic_frame.from_catalog(
database="my-home",
table_name="paradox_stream")
print("Count: {}".format(paradox_stream.count()))
paradox_stream.printSchema()
Count: 493
root
|-- time: string
|-- area.1.Casa: int
|-- area.1.zone.Soggiorno: int
|-- area.1.zone.Cucina: int
|-- area.1.zone.Bagno_Vittorio: int
|-- area.1.zone.Camera_Bambini: int
|-- area.1.zone.Bagno_Ospiti: int
|-- area.1.zone.Camera_Vittorio: int
|-- area.1.zone.Porta_Ingresso: int
|-- area.1.zone.Tamper_Sirena: int
|-- area.1.zone.Garage: int
|-- area.1.zone.Porta_Garage: int
|-- area.1.zone.Giardino_Bagno: int
|-- area.1.zone.Giardino_Cucina: int
|-- area.1.zone.Giardino_Sala: int
|-- area.1.zone.Taverna: int
|-- area.1.zone.Fumo_Garage: int
|-- partition_2: string
|-- partition_1: string
|-- partition_3: string
|-- partition_0: stringCiascun sensore di movimento è rappresentato in una colonna e può assumere valori differenti (interi) a seconda che sia attivo o meno.
Occupiamoci ora di scrivere lo script ETL che ci permetterà di elaborare i dati per identificare due diverse entità: eventi e vettori.
Eventi
Lo schema dei dati grezzi riporta su una singola riga lo stato di ciascun sensore ad un specifico timestamp. Il nostro scopo è identificare i singoli eventi, attivazione e disattivazione, di ciascun sensore e riportarli in una serie temporale.
La seguente funzione si occupa proprio di tale scopo, eliminando le colonne relative ai sensori e aggiungendo una colonna per indicare l’eventuale cambiamento rispetto all’osservazione precedente.
La colonna riporta il nome del sensore il cui stato è cambiato, seguito dal suffisso “UP” o “DOWN” a seconda che variazione identificata.
# List of events
def events(df):
w = Window().orderBy(F.col("timestamp").cast('long'))
change_column = None
for column in sensors_list:
activation = F.col(column).cast("long") > F.lag(column, 1)
.over(w)
.cast("long")
activation = F.when(activation, F.lit(' {}-UP'.format(column)))
.otherwise(F.lit(''))
deactivation = F.col(column).cast("long") < F.lag(column, 1)
.over(w)
.cast("long")
deactivation = F.when(deactivation, F.lit(' {}-DOWN'.format(column)))
.otherwise(F.lit(''))
if change_column is not None:
change_column = F.concat(change_column, activation, deactivation)
else:
change_column = F.concat(activation, deactivation)
df = df.withColumn('event', F.trim(change_column)).drop(*sensors_list)
df = df.withColumn('event', F.explode(F.split('event',' ')))
return dfApplicando la funzione al nostro set di dati, si ottiene qualcosa di simile.
df = paradox_stream.toDF()
# Cast to timestamp
df = df.withColumn("timestamp",
F.to_timestamp("time", "yyyy/MM/dd HH:mm:ss"))
.drop('time')
df_events = events(df)
df_events.show()
+----+-----------+-----------+-----------+-----------+-------------------+-------------------+
|Casa|partition_2|partition_1|partition_3|partition_0| timestamp| event|
+----+-----------+-----------+-----------+-----------+-------------------+-------------------+
| 9| 27| 10| 12| 2020|2020-10-27 12:27:53| |
| 8| 27| 10| 12| 2020|2020-10-27 12:27:55|Camera_Bambini-DOWN|
| 9| 27| 10| 12| 2020|2020-10-27 12:28:08| Camera_Bambini-UP|
| 8| 27| 10| 12| 2020|2020-10-27 12:28:12|Camera_Bambini-DOWN|
| 9| 27| 10| 12| 2020|2020-10-27 12:28:17| Soggiorno-UP|
| 8| 27| 10| 12| 2020|2020-10-27 12:28:19| Soggiorno-DOWN|
| 9| 27| 10| 12| 2020|2020-10-27 12:28:21| Bagno_Vittorio-UP|
| 8| 27| 10| 12| 2020|2020-10-27 12:28:24|Bagno_Vittorio-DOWN|
| 9| 27| 10| 12| 2020|2020-10-27 12:29:43| Bagno_Vittorio-UP|
| 8| 27| 10| 12| 2020|2020-10-27 12:29:45|Bagno_Vittorio-DOWN|
| 9| 27| 10| 12| 2020|2020-10-27 12:29:49| Bagno_Vittorio-UP|
| 8| 27| 10| 12| 2020|2020-10-27 12:29:52| |
| 8| 27| 10| 12| 2020|2020-10-27 12:29:54|Bagno_Vittorio-DOWN|
| 9| 27| 10| 12| 2020|2020-10-27 12:29:55| Bagno_Vittorio-UP|
| 8| 27| 10| 12| 2020|2020-10-27 12:29:57|Bagno_Vittorio-DOWN|
| 9| 27| 10| 12| 2020|2020-10-27 12:30:07| Cucina-UP|
| 8| 27| 10| 12| 2020|2020-10-27 12:30:10| Cucina-DOWN|
| 9| 27| 10| 12| 2020|2020-10-27 12:30:23| Cucina-UP|
| 8| 27| 10| 12| 2020|2020-10-27 12:30:25| Cucina-DOWN|
| 9| 27| 10| 12| 2020|2020-10-27 12:30:37| Cucina-UP|
+----+-----------+-----------+-----------+-----------+-------------------+-------------------+
only showing top 20 rowsVettori
Identificati gli eventi e riportati su una serie temporale, possiamo procedere all’identificazione dei vettori. Per vettore intendiamo una sequenza di eventi di attivazione (UP) avvenuti nell’arco di una finestra temporale. Immaginiamo per esempio che una persona si sposti per la casa da una stanza all’altra: avremo due eventi di attivazione relativi alla stanza di partenza e a quella di destinazione. Consideriamo concluso il vettore nel momento in cui non si rilevano ulteriori eventi di attivazione entro un certo periodo tempo prefissato.
Il codice utilizzato è il seguente.
# Find activation events vectors
timeout = 60 #seconds
w = Window().orderBy(F.col("timestamp").cast('long'))
begin_column = F.when(
F.lag('timestamp', 1).over(w).isNull(),
F.col('timestamp'))
.otherwise(
F.when(
(F.col('timestamp').cast("long") -
F.lag('timestamp', 1).over(w).cast("long")
) > timeout,
F.col('timestamp')
)
)
df_vectors = df_events.filter(F.col('event').contains('-UP'))
.withColumn('begin', begin_column)
df_vectors = df_vectors.withColumn('begin', F.last('begin', True)
.over(w.rowsBetween(-sys.maxsize, 0)))
df_vectors = df_vectors.groupBy('begin')
.agg(F.collect_list("event")
.alias('vector'))
df_vectors.show()
+--------------------+--------------------+
| begin| vector|
+--------------------+--------------------+
|2020-10-27 12:28:...|[Camera_Bambini-U...|
|2020-10-27 12:29:...|[Bagno_Vittorio-U...|
|2020-10-23 09:01:...|[Camera_Vittorio-...|
|2020-10-23 09:14:...|[Camera_Bambini-U...|
|2020-10-23 09:16:...|[Camera_Bambini-U...|
|2020-10-23 09:21:...|[Soggiorno-UP, So...|
|2020-10-23 13:43:...| [Camera_Bambini-UP]|
|2020-10-23 15:59:...|[Camera_Bambini-U...|
|2020-10-23 16:01:...| [Camera_Bambini-UP]|
|2020-10-23 16:23:...|[Camera_Bambini-U...|
|2020-10-23 17:26:...|[Camera_Bambini-U...|
|2020-10-23 17:37:...|[Cucina-UP, Cucin...|
|2020-10-23 18:05:...|[Soggiorno-UP, Cu...|
|2020-10-23 18:09:...|[Cucina-UP, Cucin...|
|2020-10-23 18:28:...| [Soggiorno-UP]|
|2020-10-23 18:39:...|[Soggiorno-UP, So...|
|2020-10-23 18:59:...|[Soggiorno-UP, So...|
|2020-10-23 19:01:...|[Soggiorno-UP, So...|
|2020-10-23 21:29:...|[Soggiorno-UP, So...|
|2020-10-23 21:31:...|[Bagno_Vittorio-U...|
+--------------------+--------------------+
only showing top 20 rowsAbbiamo ottenuto una tabella di sole due colonne, l’orario di inizio (begin) del vettore e tutti gli eventi di attivazione in ordine temporale (vector).
Ottimo! Il nostro JOB ETL si occuperà di salvare il risultato delle trasformazioni in un bucket S3.
Visualizzazione in Notebook
E’ arrivato finalmente il momento di visualizzare i nostri dati in un notebook.
Per prima cosa potremmo realizzare una heatmap in modo da indicare le stanze con il maggior numero di attivazioni. Dobbiamo quindi riprendere il risultato del nostro JOB ETL, con il quale abbiamo identificato gli eventi.
glueContext = GlueContext(SparkContext.getOrCreate())
paradox_events = glueContext.create_dynamic_frame.from_catalog(
database="my-home",
table_name="paradox_events")Calcoliamo rapidamente il numero di eventi per tipologia.
df_events_count = paradox_events.toDF()
.groupBy('event')
.count()
.toPandas()
df_events_count.set_index('event', inplace=True)Carichiamo un immagine da utilizzare come background della nostra heatmap e definiamo la posizione delle stanze.
from PIL import Image
img = Image.open("./40-Large-2-Bedroom-Apartment-Plan.jpg")
rooms = { 'Camera_Vittorio': (32,75),
'Camera_Bambini': (35,24),
'Bagno_Ospiti': (15,30),
'Bagno_Vittorio': (25,52),
'Soggiorno': (58,75),
'Cucina': (80,25)
}Ultimo passo, la visualizzazione della nostra heatmap. Per ciascuna stanza viene calcolata la posizione XY sull’immagine e disegnato un punto le quali dimensioni dipendono dal numero di occorrenze. Per questo esempio vengono prese in considerazione le sole attivazioni.
ticklx = np.linspace(0,100,5)
tickly = np.linspace(0,100,5)
xy2imgxy = lambda x,y: (img.size[0] * x / np.max(ticklx),\
img.size[1] * (np.max(tickly) - y) / np.max(tickly))
tickpx,tickpy = xy2imgxy(ticklx,tickly)
fig,ax = plt.subplots(figsize=(50,100))
ax.imshow(img)
# Rewrite x,y ticks lables
ax.set_xticklabels([])
ax.set_yticklabels([])
total = df_events_count['count'].sum()
# Add plot on the image.
for k in rooms:
px,py = rooms[k]
imgx,imgy = xy2imgxy(px,py)
size = df_events_count.loc[k+'-UP']['count']/total*100
ax.scatter(imgx,imgy,s=size*img.size[0],color="red",alpha=0.5)
# Adjust the axis.
ax.set_xlim(0,tickpx.max())
ax.set_ylim(tickpy.max(),0)
plt.show()
Vettori
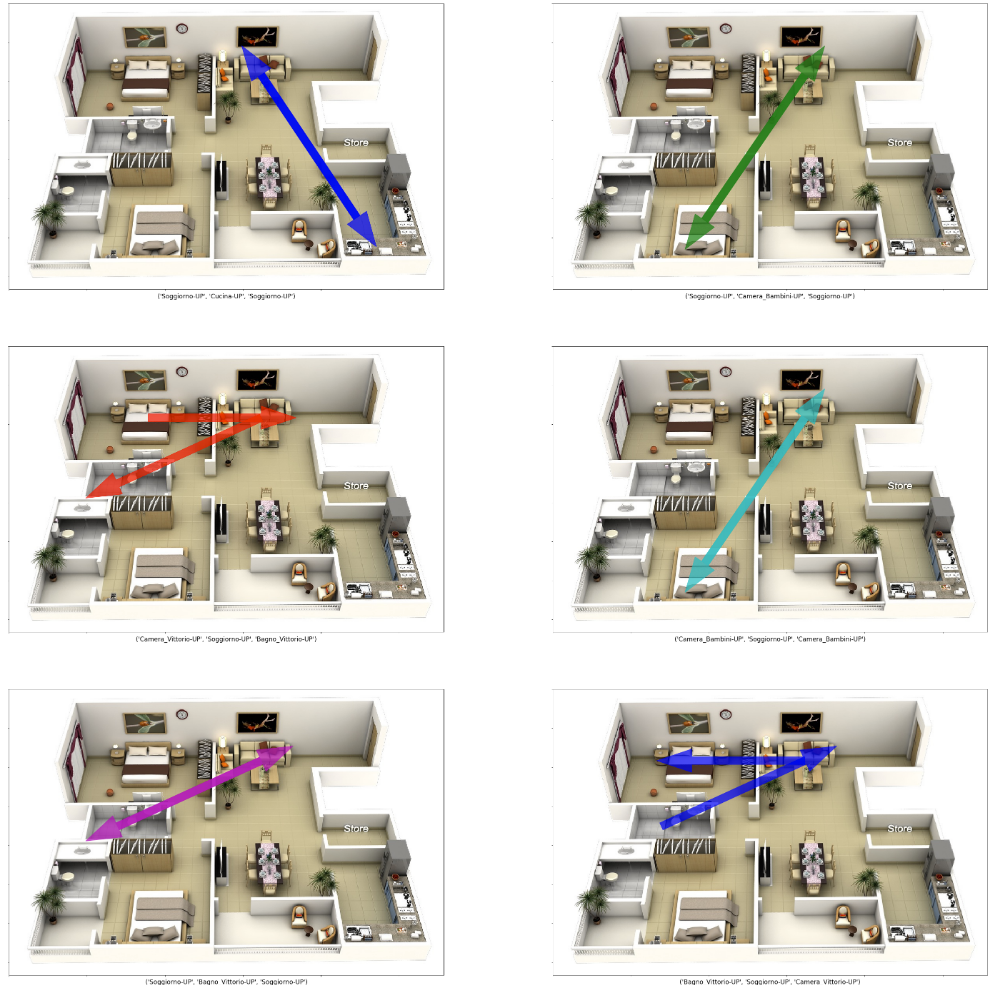
Occupiamoci ora di disegnare i vettori sulla pianta della nostra abitazione. Per farlo andremo ad identificare il numero di occorrenze di ciascuna tipologia di vettore (stessa sequenza di attivazioni) e prenderemo in esame solo i vettori più frequenti. Il codice è disponibile, come già detto, nel repository del progetto.
Il risultato è mostrato nella prossima figura.
Conclusioni
Questo “weekend project” non aveva alcun applicazione in ambito professionale. E’ nato con l’intenzione di:
- valutare le potenzialità della scraping @edge, su piattaforma Raspberry PI.
- prendere dimestichezza nella realizzazione di una data pipeline per la raccolta e l’elaborazione di dati su AWS con Kinesis Data Firehose e Glue
- divertirmi nell’analizzare le abitudini di spostamento “casalingo”!
Concludo lanciando un’idea per una possibile evoluzione di questo progetto: in che modo possiamo utilizzare i dati raccolti dai sensori di movimento?
Possiamo per esempio ipotizzare di poter addestrare dei modelli di Machine Learning per:
- determinare quante persone o addirittura identificare quali persone sono in casa?
- identificare anomalie e segnalare eventi anche quando la nostra centrale antifurto è disattivata?
Magari il prossimo weekend! Ci siamo divertiti? Alla prossima!