
Chromium e Selenium in AWS Lambda
Vediamo insieme come sia possibile utilizzare Chromium e Selenium in una funzione AWS Lambda; prima però, qualche informazione per chi non conosce questi due progetti.
Chromium è il browser open source da cui deriva Google Chrome. I browser condividono la maggior parte del codice e funzionalità. Differiscono però per i termini di licenza e Chromium non supporta Flash, non ha un sistema automatico di aggiornamento e non raccoglie statistiche di utilizzo e crash. Vedremo che queste differenze non incidono minimamente sulle potenzialità del progetto e che, grazie a Chromium, possiamo svolgere molti task interessanti nell’ambito delle nostre Lambda function.
Selenium è un notissimo framework dedicato al test di applicazioni web. A noi interessa in particolare Selenium WebDriver, un tool che consente di comandare a proprio piacimento tutti i principali browser oggi disponibili, tra cui anche Chrome/Chromium.
Perché usare Chrome in una Lambda function?
Qual’è lo scopo di utilizzare un browser in un ambiente (AWS Lambda) che non prevede una GUI? In realtà ne esistono diversi. Comandare un browser consente di automatizzare una serie di task. E’ possibile, per esempio, testare la propria web application in modo automatico realizzando una pipeline CI. Oppure, non meno importante, effettuare web scraping.
Il web scraping è una tecnica che consente di estrarre dati da un sito web e le sue possibili applicazioni sono infinite: monitorare i prezzi dei prodotti, verificare la disponibilità di un servizio, costruire base di dati acquisendo records da più fonti.
In questo post vedremo come utilizzare Chromium e Selenium in una Lambda function Python per effettuare il rendering di una qualsiasi URL.
Lambda function di esempio
La Lambda Function che andiamo a realizzare ha uno scopo specifico: data una URL, verrà utilizzato Chromium per effettuare il rendering della relativa pagina web e verrà catturata una screenshot del contenuto in formato PNG. Andremo a salvare l’immagine in un bucket S3. Eseguendo la funzione periodicamente, saremo in grado di “storicizzare” i cambiamenti di un qualsiasi sito, ad esempio la homepage di un quotidiano di informazioni online.
Ovviamente la nostra Lambda ha moltissime possibilità di miglioramento: lo scopo è mostrare le potenzialità di questo approccio.
Iniziamo con i pacchetti Python richiesti (requirements.txt).
selenium==2.53.0
chromedriver-binary==2.37.0Non sono packages normalmente disponibili nell’ambiente AWS Lambda Python: andremo quindi a creare uno zipfile per distribuire la nostra function comprensiva di tutte le dipendenze.
Otteniamo Chromium, nella sua versione Headless, cioè in grado di essere eseguito in ambienti server. Ci servirà inoltre il relativo driver Selenium. Qui di seguito i link che ho utilizzato.
Come usare Selenium Webdriver
Un semplice esempio di come usare Selenium in Python: il metodo get consente ti indirizzare il browser verso l’URL indicata, mentre il metodo save_screenshot ci permette di salvare su file un’immagine PNG del contenuto. L’immagine avrà le dimensioni della finestra di Chromium, che è impostata con l’argomento window-size a 1280×1024.
Ho deciso di realizzare una classe wrapper per il nostro scopo: effettuare il rendering di una pagina, in tutta la sua altezza. Andremo quindi a calcolare la dimensione della finestra necessaria a contenere tutti gli elementi utilizzando un trucco, uno script che eseguiremo a caricamento avvenuto. Anche in questo caso Webdriver espone un metodo execute_script che fa al caso nostro.
La soluzione non è molto elegante ma funzionale: l’URL richiesta deve essere caricata due volte. La prima volta per determinare la dimensione della finestra, la seconda per ottenere la screenshot. Lo script JS utilizzato è stato preso da questo interessante post.
Il wrapper è inoltre già “Lambda ready”, cioè gestisce correttamente i percorsi temporanei e la posizione dell’eseguibile headless-chromium specificando le chrome_options necessarie.
Vediamo come è la nostra funzione Lambda:
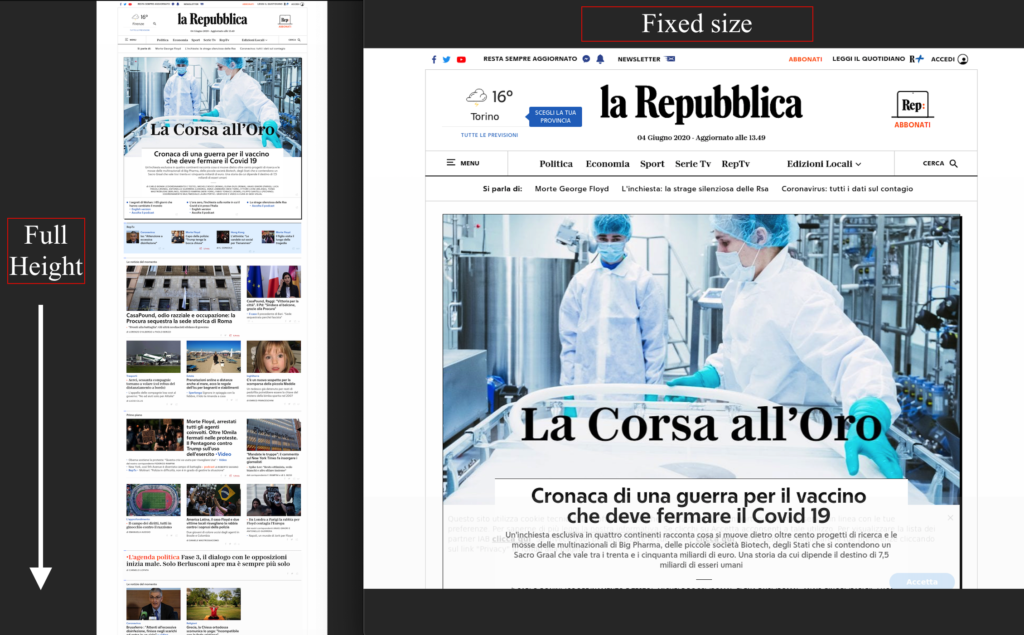
L’event handler della funzione si occupa semplicemente di istanziare il nostro oggetto WedDriverScreenshot e lo utilizza per la generazione di due screenshot: il primo con dimensione fissa della finestra (1280×1024 pixel). Per il secondo viene invece omesso il parametro Height che sarà determinato automaticamente dal nostro wrapper.
Ecco le due immagini risultanti, messe a confronto tra loro, relative al sito www.repubblica.it
Deployment della funzione
Ho raccolto in questo repository Github tutti i file necessari al deployment del progetto su AWS Cloud. Oltre ai file già analizzati in precedenza, è presente un template CloudFormation per il deployment dello stack. La sezione più importante riguarda ovviamente la definizione della ScreenshotFunction: alcune variabili di ambiente come PATH e PYTHONPATH sono fondamentali per la corretta esecuzione della function e di Chromium. E’ necessario, inoltre, tenere in considerazione i requisiti di memoria ed il timeout: il caricamento di una pagina può impiegare infatti diversi secondi. Il percorso lib include alcune library necessarie all’esecuzione di Chromium e non presenti di default nell’ambiente Lambda.
Come di consueto mi sono affidato ad un Makefile per l’esecuzione delle operazioni principali.
## download chromedriver, headless-chrome to `./bin/`
make fetch-dependencies
## prepares build.zip archive for AWS Lambda deploy
make lambda-build
## create CloudFormation stack with lambda function and role.
make BUCKET=your_bucket_name create-stack Il template CloudFormation prevede un bucket S3 da utilizzare come source per il deployment della Lambda function. Successivamente lo stesso bucket verrà utilizzato per memorizzare gli screenshot PNG.
Conclusioni
Abbiamo utilizzato Selenium e Chromium per effettuare il rendering di una pagina web. Si tratta di una possibile applicazione di questi due progetti in ambito serverless. Come anticipato, un’altra applicazione molto interessante è il web scraping. In questo caso, l’attributo page_source di Webdriver consente di accedere ai sorgenti della pagina e un package come BeautifulSoup può essere molto utile per estrarre i dati che intendiamo raccogliere. Il pacchetto Selenium per Python mette a disposizione diversi metodi per automatizzare altre operazioni: consiglio di guardarsi l’ottima documentazione.
Vedremo un esempio di web scraping in uno dei prossimi post!
Ci siamo divertiti? Alla prossima!